by James Wallace Harris, 1/7/26
Don’t bother reading this essay unless you’re considering the following:
- Want to cancel your subscription to a cloud storage site
- Manage terabytes of data
- Hope to convert your old movies on discs to Jellyfin or Plex
- Want to run Linux programs via Docker
For the past few years, I’ve been watching YouTubers promote NASes (Network Attached Storage). Last year, I just couldn’t help myself, I bought a UGreen DXP2800. I’m not sure I needed a NAS. Dropbox has been serving me well for over fifteen years.
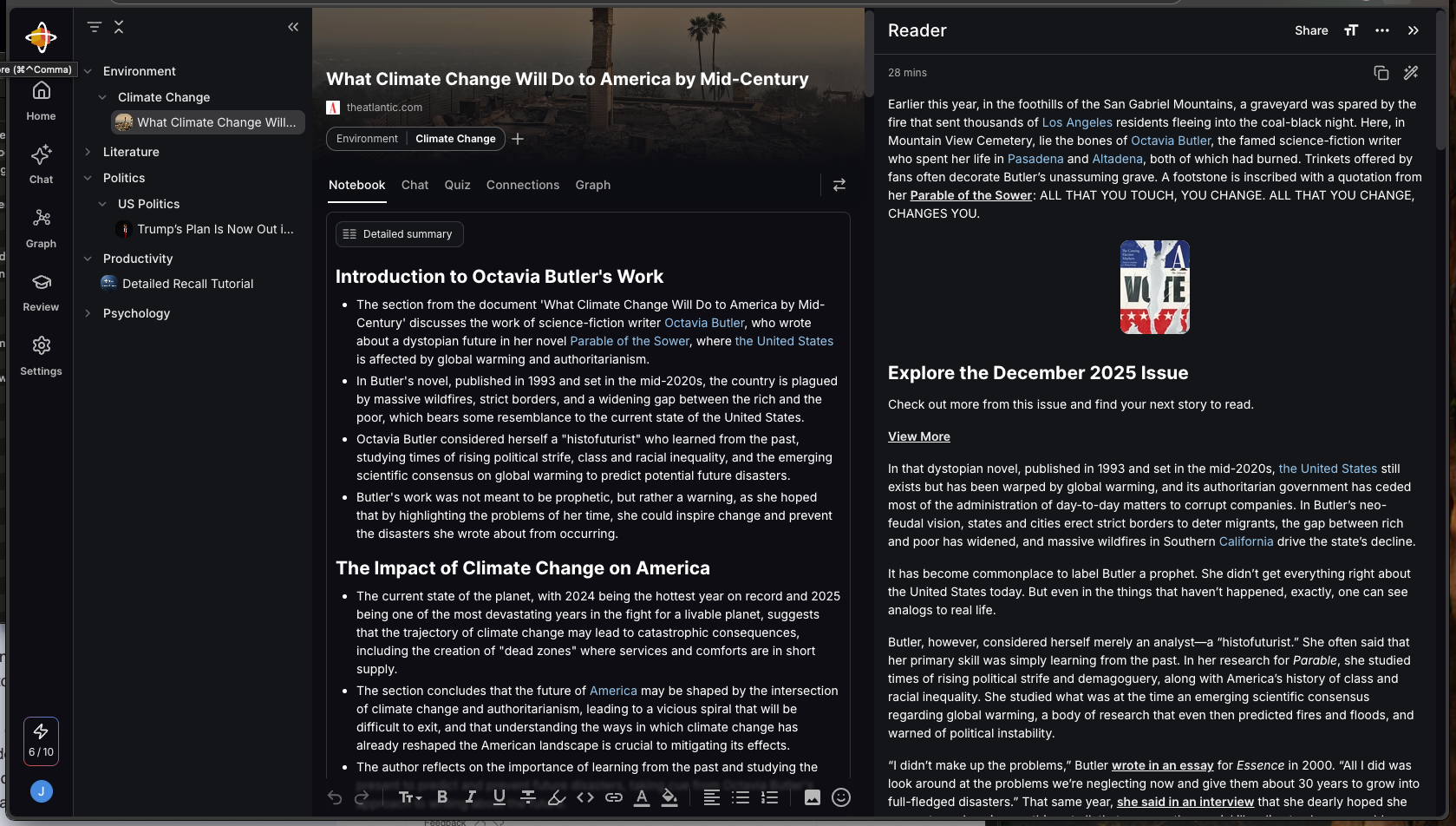
[My DXP2800 is pictured above on top of a bookcase. It’s connected to a UPS and a mesh router. It’s a little noisy, but not bad.]
Actually, I loved Dropbox until I figured it was the reason my computers ran warm and noisy. I assume that was because it routinely checked tens of thousands of my files to keep them indexed, copied, and up-to-date on my three computers, two tablets, and an iPhone.
Lesson #1. If you desire simplicity, stay with the cloud. My old system was to use Dropbox and let it keep copies of my files locally on my Windows, Mac, and Linux machines. I figured that was three copies and an off-site backup. That was an easy-to-live-with, simple backup solution. However, I only had 2TB of files, which Dropbox charged me $137 a year to maintain.
Moving to the UGreen DXP2800 meant accessing all my files from the single NAS drive. It’s cooler and quieter on my computers. However, I had to purchase two large external drives for my Mac and Windows machines that I use to automatically back up the NAS drive daily.
Thus, my initial cost to leave Dropbox was the cost of the DXP2800 and two 16TB Seagate drives for a RAID array ($850), plus $269 (20TB external drive). I already had an old 8TB external drive for the other backup. And if I want an off-site backup, I need to physically take one of my drives to a friend’s house, or pay a backup company $100-200 a year.
And I have more to back up now. I was running Plex on my Mac using a 4TB SSD. Basically, I ripped a movie when needed. Since I got the UGreen DXP2800 and 12TB of space, I’ve been ripping all my movies and TV shows that I own on DVD and Blu-ray. I’ve ripped about half of them, and I figure I’ll use up 8-10TB of my RAID drive space.
I’ve been working for weeks ripping discs. I had no idea we had accumulated so many old movies and TV shows over the last thirty years. Susan and I had gotten tired of using a DVR/BD player, so we shelved all those discs on a neglected bookcase and subscribed to several streaming services.
When I bought the UGreen DXP2800, I thought we could cancel some of our subscriptions. We are viewing our collection via Jellyfin, but we haven’t canceled any streaming services.
I should finish the disc ripping in another couple of weeks. At least I hope. It’s a tedious process. My fantasy is having this wonderful digital library of movies and television shows we love, and we’ll rewatch them for the rest of our lives. I even fantasized about quitting all our streaming services. But I don’t think that will happen.
Looking at what TV shows Susan and I watched during 2025, none were from our library. Susan has started rewatching her old favorite movies. She especially loves to watch her favorite Christmas movies every year. And I have talked her into watching two old TV shows I bought on disc years ago, The Fugitive and Mr. Novak. Both shows premiered in 1963, and neither is on a streaming service.
Lesson #2. It would taken much less effort to just watch the shows on disc. And when I’ve converted them, I will have 10TB of data that I must protect. It’s a huge burden that hangs over my head.
Lesson #3. I tried to save money by using the free MakeMKV program. It works great, but creates large files and is somewhat slow. I eventually spent $40 for WinX DVD Ripper for Mac. It’s faster and creates smaller .mp4 files. However, it doesn’t rip BD discs. I found another Mac program that will, but it will cost another $49. I bought a $39 program for the PC to rip Blu-ray discs, but it was painfully slow. They claimed to have a 90-day money-back guarantee, yet the company ignored my request to return my money. It pisses me off that there are several appealing ripping programs I’d like to try, but they all want their money up front. Most offer a trial that will run a 2-minute test. That’s not enough. I’m happy with WinX DVD Ripper for Mac; I just wish it ripped Blu-rays.
Even then, files that are ripped from Blu-ray movies are huge and take much longer to rip. I’m not sure Blu-ray is worth it.
I tend feel movies and TV shows look better on streaming services. Most people won’t notice. My wife doesn’t see the difference between DVD and BD. For ripping, I prefer DVDs.
Lesson #4. I bought the UGreen NAS even though I wanted a Synology NAS. UGreen just had better hardware. I thought I wanted to get into Docker containers, and UGreen had the hardware for that at the price I wanted to pay. However, setting up Docker containers requires a significant amount of Linux savvy.
I kind of wish I had gotten Synology. It runs many programs natively, so you don’t have to mess with Docker. I hope UGreen will do more of that in the future. I spent days trying to get the YACReader server running. I never succeeded. That was frustrating because I really want it.
There are many services I’d like to run, but I just don’t have the Docker and Linux skills.
Final Thoughts
I’m not sure I would buy a NAS, knowing what I know now. However, if I could figure out how to run programs via Docker, I might go whole hog on NASes. In which case, I would regret getting the 2-drive DXP2800. At first, I thought I’d be good getting two 8TB drives to put into RAID. But I spent more for two 12TB drives, just in case. If I really get into having a home lab, I should have bought the 4-drive DXP4800 Plus.
There are many features I wish UGreen would offer for its software. If all the programs I wanted to run ran natively on the UGreen OS and were easy to use, I think I would love having a NAS.
Setting up file sharing was easy. I got it working on my Mac, Windows, Linux, Android, iPad, and iPhone. However, it’s hard to open files using the UGreen app on iOS and Android. I don’t know why UGreen just can’t make an all-purpose file viewer. Dropbox can open several file types on my iPhone. UGreen expects me to save the file to my iPhone and then view it with an iPhone app. However, I can’t get my iPhone apps to find where the UGreen app saved the file.
That’s why I want the YACReaderLibrary Server running on the DXP2800. I have YACReader running on every device. It can read .pdf, .cdr, .cdz, .jpg, .png, .tiff, and more. Too bad it doesn’t read Word and Excel files too. I think other Linux server apps can handle even more file types. I want my NAS to be a document server.
I’m moving forward with my NAS. If I fail, I’ll regret buying the NAS. Or, I might create a server full of useful apps that I can’t live without. That sounds fun, but it also sounds like it could become a lifelong burden.
JWH